Organizations may be using RabbitMQ, JMS, and AMQP for messaging service and handle the producer consumer problem, but these tools are not for huge amount of data to process and store, and now a days to backup all the data is important. But this are not use to backup the data, these tools are used for single time message processing which means once the consumer process the message, the message is delete from the disk after processing because this tools are not use to create logs to store the previous activities. But after Apache Kafka all the problems are resolve, because it is use to collect and analyze huge amount of data at real time and its messages/data are persist on disk and replicate with in the cluster to prevent data loss, and consumer can check current data as well as previous data because of maintaining logs by Apache Kafka.
What is Apache Kafka :-
Apache Kafka is distribute publish subscribe messaging system, which is use to handle high volume of data. It is use in both conditions offline as well as online. Its message are persist on disk and replicated with in the cluster to prevent data loss. Build on top of Zookeeper Synchronization service. Integrates with Apache Storm and Spark for real time streaming data analysis.
Benefits of Apache Kafka :-
- Reliability – Kafka is distributed, partitioned replication and fault tolerance.
- Scalability – Scales easily without downtime.
- Durability – Kafka uses “Distributed commit log”, means message persists on disk as fast as possible.
- Performance – For publishing and subscribing messages Kafka has high throughput, it maintains performance when TB of messages are stores.
- Kafka guarantees zero data loss and zero downtime with very good performance.
Use Cases of Apache Kafka :-
- Metrics – It is use for operational monitoring data (collecting key system performance of metrics at periodic intervals over time), it includes aggregating statistics from distributed applications.
- Log Aggregation Solution – Collect logs across organization and make them available in standard format.
- Stream Processing – Kafka strong durability is use in context of stream processing.
- Kafka Messaging – Kafka has better throughput, built-in partitioning, replication, and fault-tolerance, in comparison to most other messaging systems. That makes it a good solution for large-scale message processing applications.
- Website Activity Tracking – It is use to rebuild a user activity tracking pipelines as a set of real-time publish-subscribe feeds, That implies site activity is publish to central topics with one topic per activity type. Here, site activity refers to page views, searches, or other actions users may take.
- Kafka Event Sourcing – Event Sourcing ensures that all changes to application state are store as a sequence of events. Not just can we query these events, we can also use the event log to reconstruct past states, and as a foundation to automatically adjust the state to cope with retroactive changes.
- Commit Log – Comes to a distributed system, Kafka can serve as a kind of external commit log for it.
Apache Kafka Fundamentals :-
- Topics – Stream of message belonging to a particular category.
- Partitions – Handle arbitrary amount of data.
- Partition Offset – Unique sequence id called “offset”.
- Replicas of Partition – Backups of a partition.
- Brokers – Maintain the published data.
- Kafka Cluster – Group of brokers, we can expand them without downtime.
- Producers – Publisher of message and send data to brokers.
- Consumers – Read message from brokers.
- Leader – Each partition has one server act as a leader and also take care of read as well as write operations for the given partition.
- Followers – Follow leader instruction, pull message and updates it own data store.
Apache Kafka Cluster Architecture :-
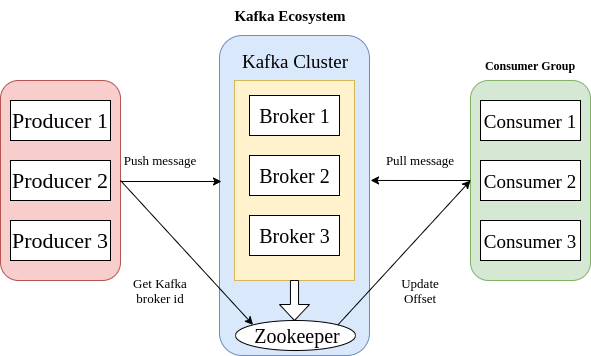
- Brokers – Kafka cluster contains multiple brokers to maintain load balance. To maintain their states they come under zookeeper, because they are stateless. Single broker can handle hundreds of thousands of read and write per second. The leader election is done by zookeeper in Kafka brokers.
- Zookeeper – Use to manage Kafka broker, and mainly used to notify producer and consumer about broker fails.
- Producer – Use to push data to brokers, and when new broker is start all producer is use to send message to that broker.
- Consumer – Use to pull data from broker and the offset value is notified by zookeeper.
Apache Kafka Workflow :-
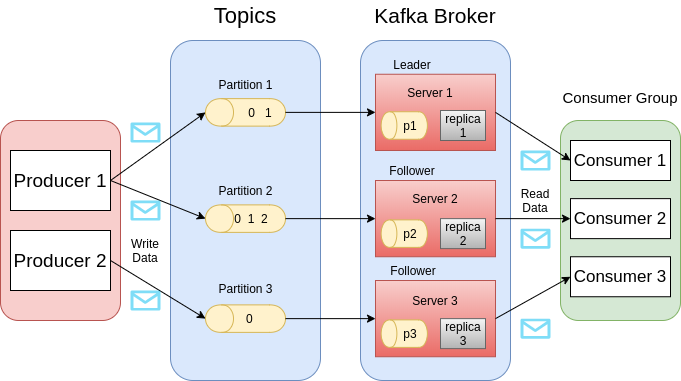
Publish Subscribe Workflow :-
- Producers send messages to the topic frequently.
- After receiving the messages from the producer, broker stores all the messages in the partitions which are arranged for that particular topic. Broker’s other responsibility is to distribute the messages uniformly. For example, if a broker gets four messages, and there are four partitions, then the broker will store one message in each partition.
- Now consumer subscribes to a particular topic.
- When the consumer subscribes to a topic, Kafka will give the current offset of the topic to the consumer and stores the offset in the Zoo-Keeper’s ensemble.
- Consumer frequently requests Kafka for new messages.
- After receiving the messages from the producer, Kafka forwards them to consumers.
- Then consumer will process them.
- After processing the messages, then consumers send recognition to the Kafka broker.
- After receiving the acknowledgement, then it updates the offset value and updated value is stored in Zoo-Keeper.
- The above workflow is repeated until the consumer is requesting the resource.
- At any moment, the consumer can rewind/skip to the required offset of a topic and read all ensuing messages.
Queue Messaging Workflow :-
- At regular intervals, producers send messages to a topic.
- Like the earlier strategy, messages are store by Kafka in the partitions design for that particular topic.
- One consumer subscribes to a particular topic say “topic1” with “Group ID” say “Gr1”.
- The communication between Kafka and consumer is carried out in the same manner as the publish subscribe messaging system until the new consumer subscribes to the topic.
- After the arrival of the new consumer, then Kafka change its function to share mode, to share the messages between the old consumer and new consumer. This process of sharing is continue till the number of consumers equals the number of partitions designed for that topic.
- When the number of consumers surpasses the number of partitions, then the new consumer will not receive any subsequent message until any current consumer unsubscribes. This situation emerges because, in Kafka, every consumer is allocate with at most one partition. When all the partitions are allocate to current consumers, then new consumers have to wait for the partition.
Enterprise Use Apache Kafka :-
- Twitter – Twitter is an online social networking service that provides a platform to send and receive user tweets. Registered users can read and post tweets, but unregistered users can only read tweets. Twitter uses Storm-Kafka as a part of their stream processing infrastructure.
- LinkedIn – Apache Kafka is used at LinkedIn for activity stream data and operational metrics. Kafka messaging system helps LinkedIn with various products like LinkedIn News-feed, LinkedIn Today for online message consumption and in addition to offline analytics systems like Hadoop. Kafka’s strong durability is also one of the key factors in connection with LinkedIn.
- Netflix – Netflix is an American multinational provider of on-demand Internet streaming media. Which uses Kafka for real-time monitoring as well as event processing.
- Mozilla – Kafka will soon be replacing a part of Mozilla current production system to collect performance and usage data from the end-user’s browser for projects like Telemetry, Test Pilot, etc.
- Oracle – Oracle provides native connectivity to Kafka from its Enterprise Service Bus product called Oracle Service Bus which allows developers to leverage Oracle Service Bus built-in mediation capabilities to implement staged data pipelines.
For more details Click Here

Be the first to comment.