
AWS Data Pipeline is a web service that can be used to automate the movement and transformation of data. All you need to do is to define a workflow that will be followed in order to successfully transmit the data along with some parameters required for the same.
Why we need AWS Data Pipeline services ?
While performing any kind of data transformation activities, you have to bother about the consequences that come in picture if your data doesn’t arrive on time or one of your processing steps fails. But you don’t really have to worry about this stuff rather you have focus on the business logic which is actually going to create value for your organisation. Therefore, data pipeline makes us to ignore all these activities so that we could focus on business logic and this way everything else will automatically work in our favour.
How does Data Pipeline work ?
The following components of data pipeline work together to manage your data :
- Pipeline Definition : It specifies the business logic of your data management.
- Pipeline Schedules & Tasks : After uploading pipeline definition to your pipeline, you can activate the pipeline and edit pipeline definition for the running pipeline. You can also deactivate the pipeline, modify the data source and then activate the pipeline again.
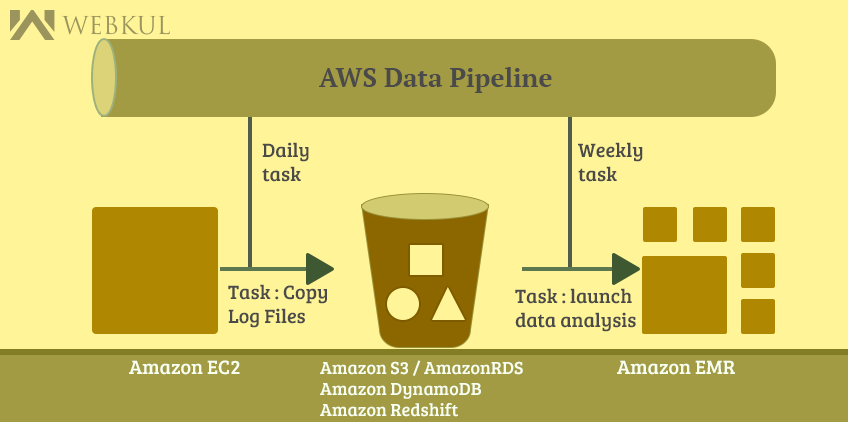
- Task Runners : As you create pipeline definitions, a task runner is automatically installed and runs on your pipeline resources such as it could copy log files to Amazon S3 and launch an Amazon EMR cluster and many more based on your want you want to perform.
At very high level, data pipeline consists of the data nodes & Activity. To better understand this :
- Input Datanode : This is required to hold your data and it could be a directory in S3 bucket or a dynamoDB table on a relational database.
- Activity : Activity is the work to be performed. It could be a sql query, a script running on EC2 instance or an EMR job which is going to produce complex logs after some complicated real time data analysis.
- Output Datanode : Typically, your activities are going to generate even more amount of data. For example, if you have a sql query, you can have an output that probably just don’t want to drop on floor. If you have an EMR job, again since you have paid for the analysis you would definitely want to keep the data. Therefore, you need something to store your processed data on. But there might be some cases where you don’t need to store your processed data such as your activities are just sending emails and messages to multiple clients.So, it is not mandatory to always have an output datanode but in general we would recommend you to have one.
To store data, AWS Data Pipeline works with the Amazon Dynamo DB, Amazon RDS, Amazon Redshift and Amazon S3. On the other hand, to perform the data transmission it uses two compute services i.e. Amazon EC2 & Amazon EMR.
For different kind of applications, you might be using different data stores. For example if you are generating large amount of event type data or you have real time I/O needs, using Amazon Dynamo DB is recommended for better throughput.But if you have to store lots of objects such as web server’s log etc using S3 would be a better option.
Similarly, Amazon RDS is recommended for user demographics and for historical usage stats, a data warehouse Amazon Redshift should be used. But loading data into Amazon Redshift is not that simple because you don’t have to blindly shift the data from S3, Dynamo DB or RDS to Redshift data warehouse. Since the data is unstructured, all you need to do is to perform some analysis on your data using Amazon EMR and then think about loading it into Redshift’s relational data warehouse after it becomes structured. And this entire process of data transformation can be automated using Data Pipeline.
Example Scenario : Content Targetting
Suppose you have a website with premium content and your goal is to improve the website by better targetting this content. You could show every user all the content available on your website but you could do a lot better if you show specific users the things that you think they are likely want to see or purchase. This way, your goal is to improve your target and business but your secondary goal is not to break or rewrite the content of your website for performing the same. So you must try your data to be more friendly to analytics by generating logs in some format and storing data in existing databases.
Example Scenario : Web Server’s Traffic Analysis
AWS data pipeline can be used to archive your web servers logs to Amazon S3 each day and then run a weekly Amazon EMR cluster over those logs to generate traffic. It also ensures that Amazon EMR cluster waits for the final week day for the data to be uploaded to Amazon S3 before it begins its analysis.
For a more practical approach to Amazon Data Pipeline, please refer to our next blog !!
IN CASE OF ANY QUERY, PLEASE CONTACT US