An organization keeps its data in different systems, which support various business processes. In order to create an overall picture of business operations, customers and suppliers, the data must come together in one place and made compatible. Both external (from the environment) and internal data (from ERP, CRM and financial systems) should merge into a central location and permanent storage space for reporting and data analysis, such system is known as Data Warehouse.
Data analytics are important for business but building a traditional data warehouse may have the following drawbacks :
- Data warehouses are complex, can take months to setup and cost you millions of dollors in software and hardware expenses.
- Once you have made the investment and final setup, you have to hire bunch of DBAs to make sure that your queries run fast and data is never lost.
- These data warehouses don’t scale up and down easily so when data volume grows, you have to choose between slow query performance or timing effort on an extensive upgrade process.
What if you could replace all those software and hardware with a data warehouse service which is easy to use, scale and cost effective ?
Yes, Amazon Redshift is a fast, fully managed, petabyte-scale data warehouse that makes it easy for you to setup, manage and scale your data warehouse.It also provides you cost-effective way to analyze all your data using your existing business intelligence tools.
The entire process of creating our data warehouse can be summerized in the following steps :-
First, we need to create an amazon redshift cluster :-
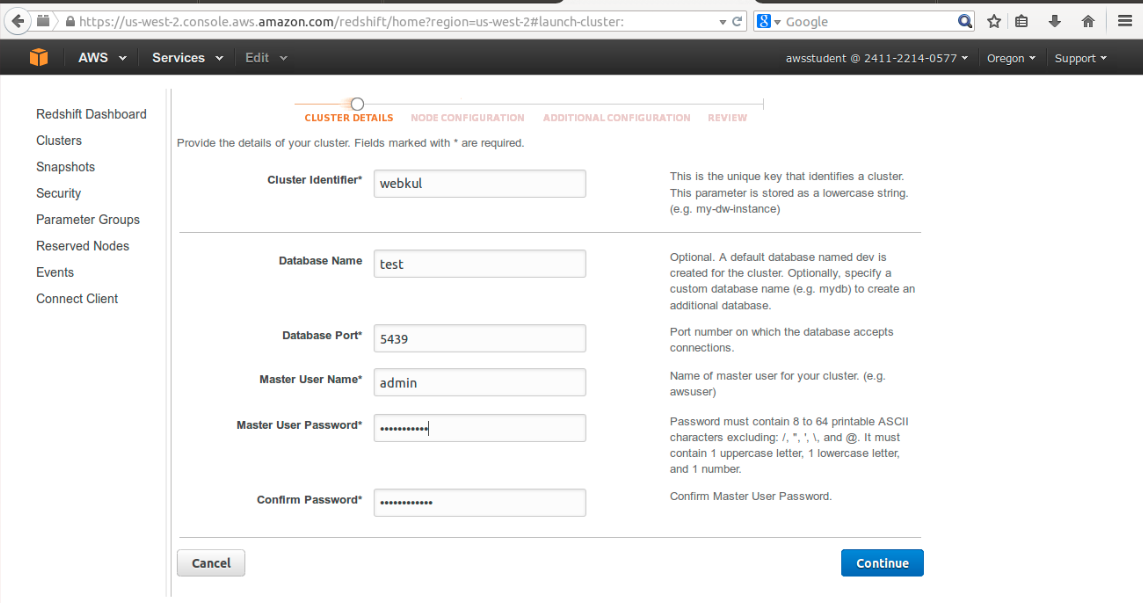 Choose the default settings for rest of the configuration and click on launch cluster.
Choose the default settings for rest of the configuration and click on launch cluster.
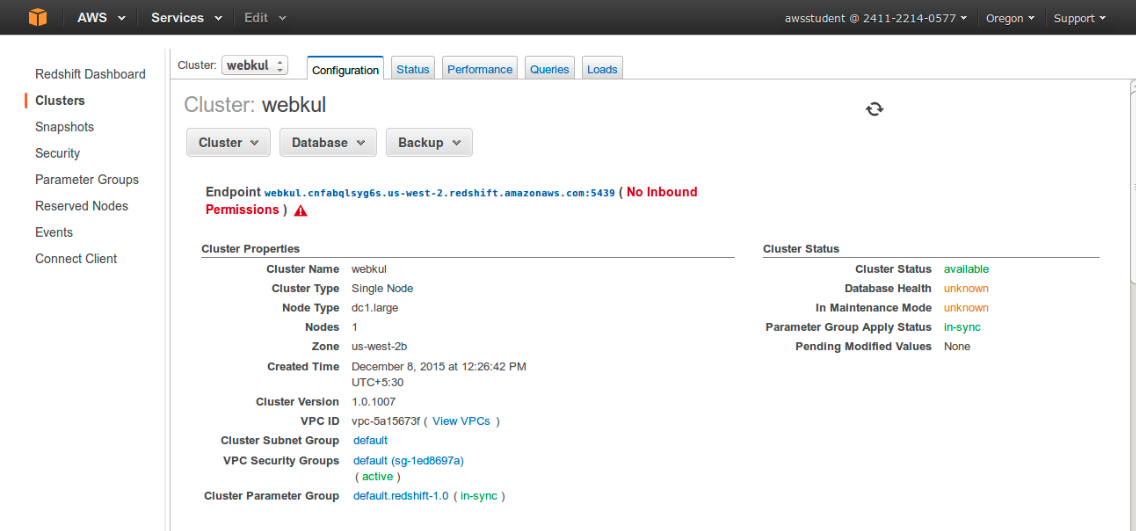
Connect any query tool of your choice.Here we are taking the example of jackdb, which is a browser based interface for writing queries.Login to jackdb and add a datasource for amazon redshift.
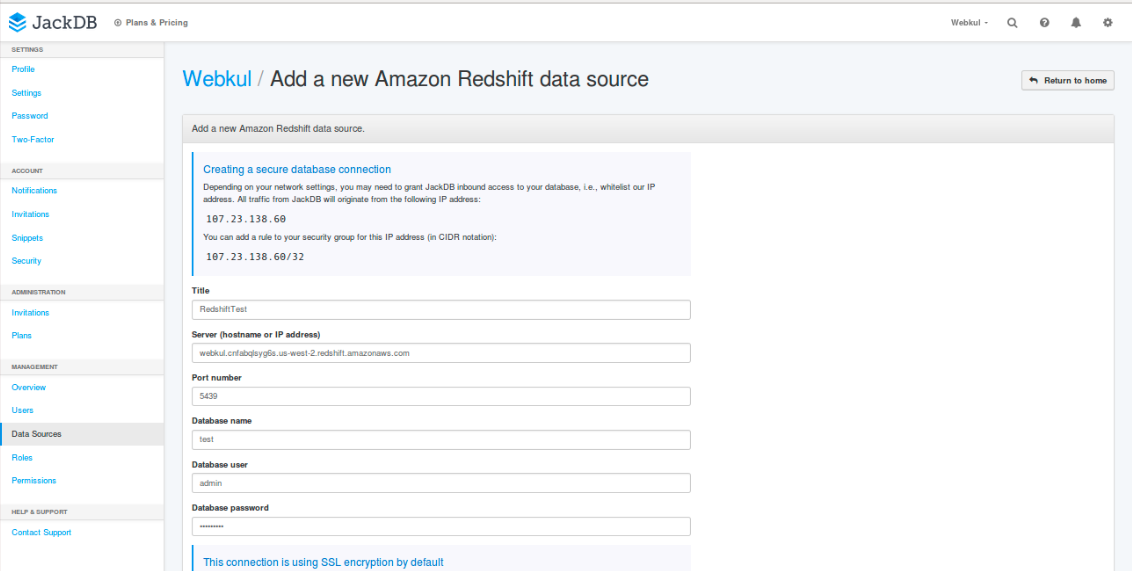
- In the server hostname or ip section, enter the end point name as displayed on aws redshift console without “:5439” port number.
- Don’t click on the create data source button before adding an inbound security group rule for jackdb.
Depending on your network and security settings, you may need to enter an inbound rule for the specified query tool in order to connect it to your redshift cluster.
Switch on aws console, click on default security group :-
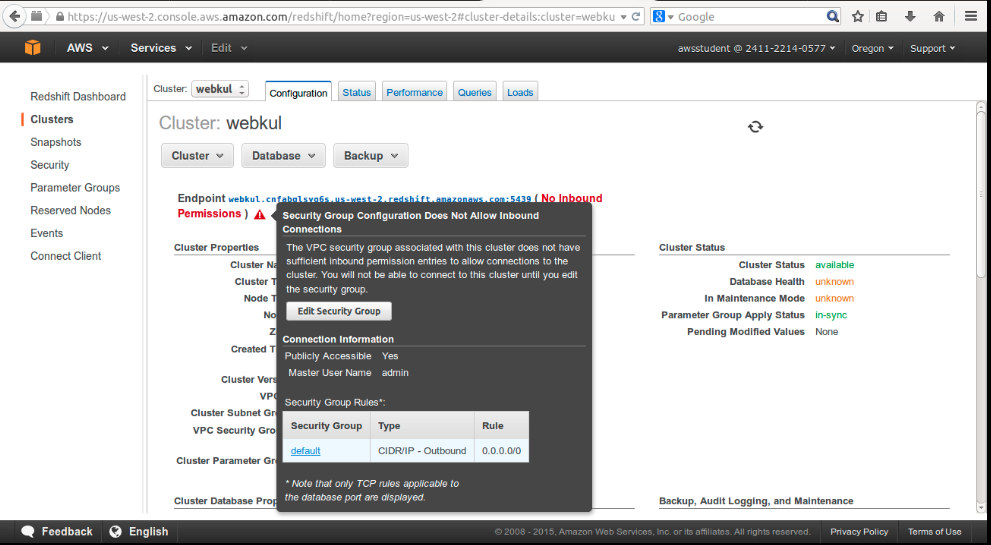
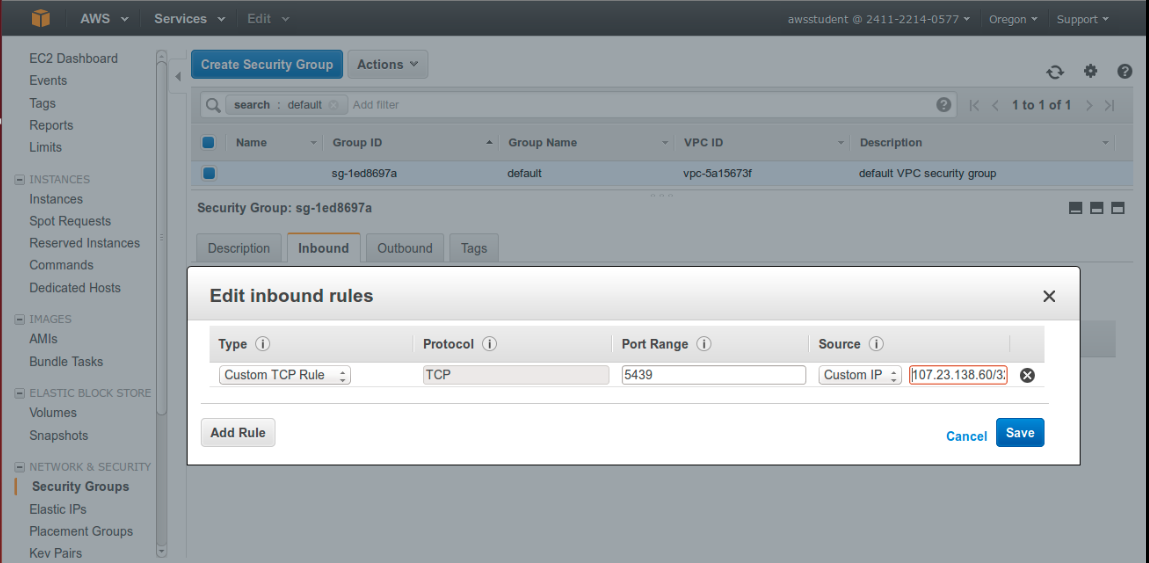
Add a inbound TCP rule for Jackdb’s ip (here it is 107.23.138.60/32) on port 5439 :-
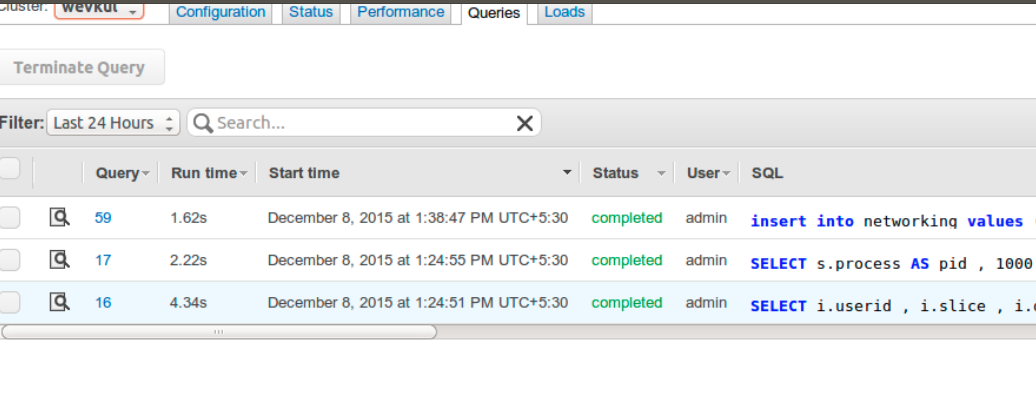
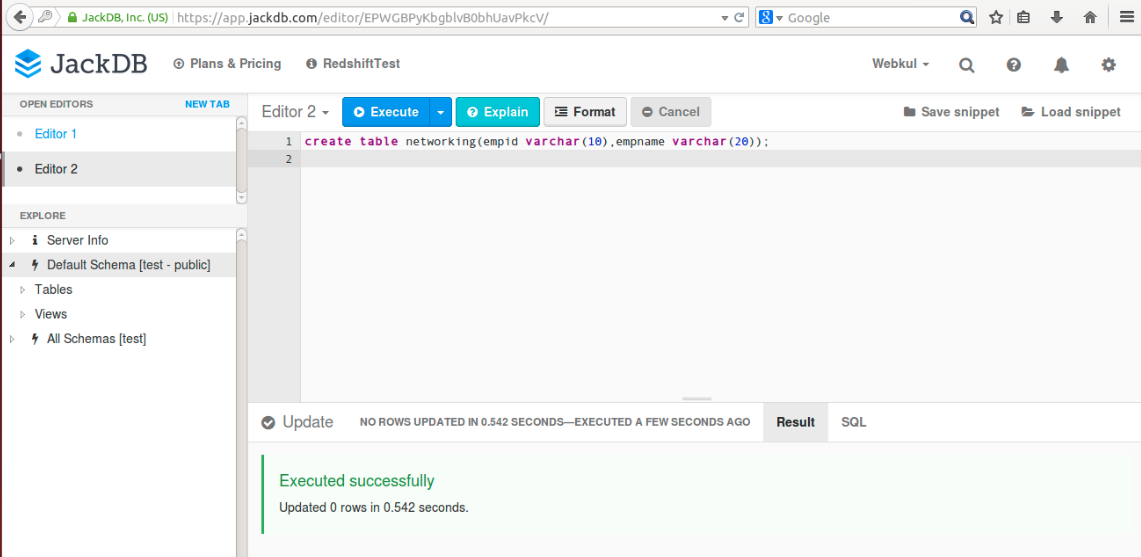
Now, you can switch to jackdb console and click on create datasource. After successfully establishing a connection with aws redshift cluster, you must get a console as shown below. Now you can execute any query on your ‘test’ database :-
You can verify whether the queries have been executed on your database or not by clicking on queries section of redshift cluster :-